
Integrated Management of Large-Scale Actions
Improving the process for adding and refreshing large amounts of data, making it easier for data analysts to find the data they need.Problem statement
For effective business decision-making, data products must be easy to find, up-to-date, and relevant. However, maintaining large datasets is often time-consuming and prone to errors. Customer feedback highlighted that the existing process for uploading and editing data was too long and not transparent enough, hindering the efficient upkeep of data products.
Customer feedback indicated that our platform caters well to technically skilled users but often leaves less technical data owners feeling disadvantaged and reliant on data engineers for tasks.
Solution
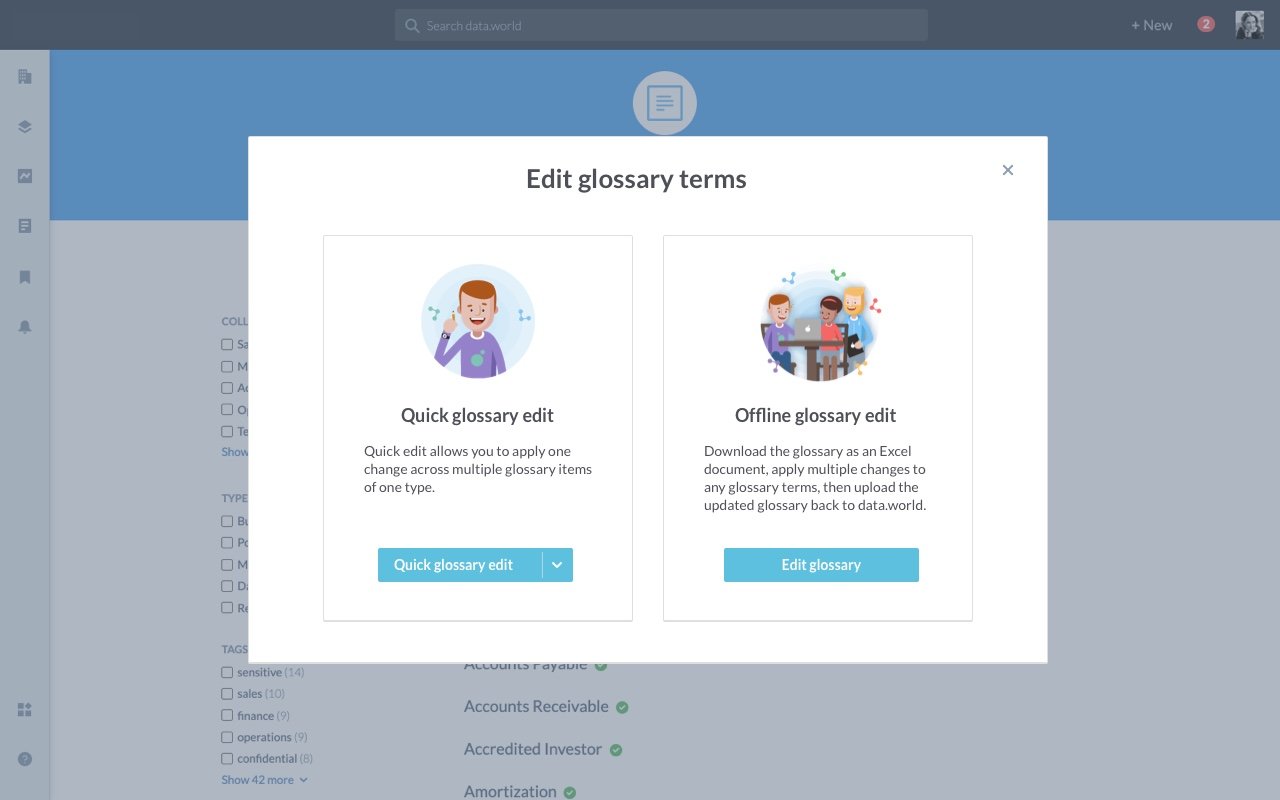
We've added a feature to the platform's UI allowing less technical users to download particular data products, modify them in batches in the tools they are familiar with, such as Microsoft Excel, and then re-upload the document to apply these changes.

Key user personas
-
The primary persona, responsible for creating and updating data products within their domain.
-
The secondary persona, often engaged in data maintenance. These highly technical users manage data ingestion and migration, relying on scripting and APIs for repetitive tasks.
Lead designer
my role on the projectMy responsibilities
Developing an initial design prototype using internal data.
Creating a research proposal for the initial prototype.
Conducting a study to evaluate the usability of the initial design prototype.
Refining the initial prototype into a final design solution based on user feedback.
Partnering with engineering teams to enhance the final design's feasibility.
-
The data platform supported custom data product types. To ensure a manageable scope and to validate the proposed solution, the first project phase addressed only a subset of data products which was commonly used by the majority of customers.
-
A key decision in the project was choosing between an in-browser editing model and a download-and-reupload model. After considering engineering limitations and customer feedback, the download-and-reupload model was selected.
-
The project timeline was stretched due to changing priorities. This resulted in a considerable overhead caused by the need for knowledge transfer among rotating project members.
Project constrains
Design Process
The project began with a comprehensive kickoff meeting involving Engineering, Product, and Design. Following this workshop, I created a high-fidelity design prototype for testing with users from our customer base.
Value and usability research
I held 4 one-on-one 30 minute interviews with users.
When choosing participants, I followed these criteria:
The participant's customer use case aligns with the feature's intended use case.
The participant belongs to the target user persona group.
There is a wide range of technical abilities within the selected participants.
Research findings
I successfully validated the suggested design approach for the initial MVP, and identified usability improvements for individual screens in the feature flow.
“I love the concept. [The concept] is fantastic! Something that we will use a lot.”
— Data governance analyst
“This would be great, and it’d help a lot.”
— Data architect
Examples of screen and flow improvements
Participants requested restricting user access to only those data product fields for which they have permissions, essentially integrating access control into the editing process.
The visual cues for adding a new product (green plus icon) and updating an existing one (yellow delta icon) were not clear enough for users to differentiate effectively.
Development
I worked closely with engineering teams throughout this project's development. We faced numerous engineering challenges that emerged during development, significantly impacting the design.
Originally, I planned for short in-line error messages to inform the user about errors and warnings during upload. However, in development, it became apparent that:
There were too many possible error messages, causing layout problems.
The platform-generated error messages were too technical and too wordy for less technical users.
The design of warning messages was too intimidating, often leading users to cancel their data uploads entirely.
Outcomes
The initial MVP release and subsequent follow-up releases garnered exceptional customer satisfaction. Through click-through metrics and feedback from the customer success team, it's evident that the new feature has substantially shortened the duration of a typical data upload and edit process.
The average length of the initial glossary upload decreased from 3 days to 4 hours
Furthermore, it empowered less technically inclined users to independently manage their tasks, thereby reducing their reliance on data engineers and tech-support tickets.